
阿里云基于全新 RocketMQ 5.0 内核的落地实践
前言
在上个月结束的 RocketMQ Summit 全球开发者峰会中,Apache RocketMQ 社区发布了新一代 RocketMQ 的能力全景图,为众多开发者阐述 RocketMQ 5.0 这一大版本的技术定位与发展方向。
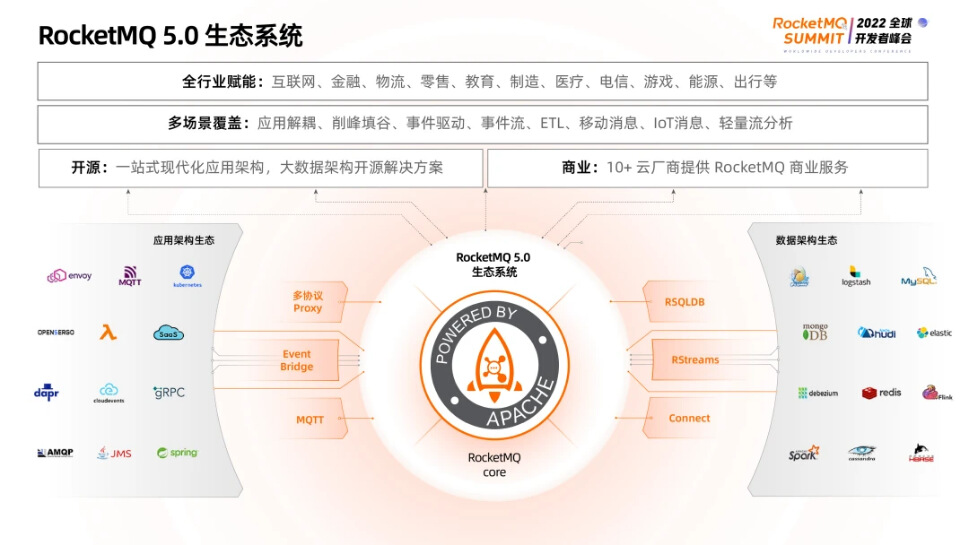
在过去七年大规模云计算实践中,RocketMQ 不断自我演进,今天,RocketMQ 正式迈进 5.0 时代。
从社区关于 5.0 版本的解读可以看到,在云原生以及企业全面上云的大潮下,为了更好地匹配业务开发者的诉求,Apache RocketMQ 做了很多的架构升级和产品化能力的适配。那么如何在企业的生产实践中落地 RocketMQ 5.0 呢?本篇文章的核心就消息架构以及产品能力的云原生化,介绍了阿里云是如何基于全新的 RocketMQ 5.0 内核做出自己的判断和演进,以及如何适配越来越多的企业客户在技术和能力方面的诉求。
云原生消息服务的演进方向
首先我们来看下云原生消息服务有哪些演进?
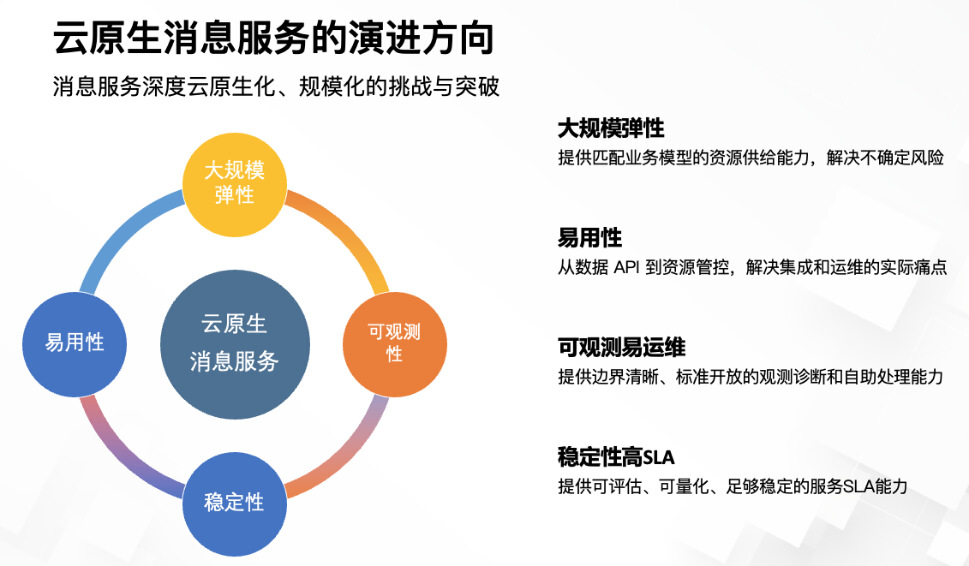
面向未来,适应云原生架构的消息产品能力应该在以下方面做出重要突破:
-
大规模弹性:企业上云的本质是解放资源供给的负担和压力,专注于业务的集成和发展。作为消息服务的运维方,应该为上层业务提供与模型匹配的资源供给能力,伴随业务流量的发展提供最贴合的弹性能力。一方面可以解决面向不确定突发流量的系统风险,另一方面也可以实现资源利用率的提升。
-
易用性:易用性是集成类中间件的重要能力,消息服务应该从 API 设计到集成开发、再到配置运维,全面地降低用户的负担,避免犯错。低门槛才能打开市场,扩大心智和群体。
-
可观测性:可观测性对于消息服务的所有参与方来说都很重要,服务提供方应提供边界清晰、标准开放的观测诊断能力,这样才能解放消息运维方的负担,实现使用者自排查和边界责任的清晰化。
-
稳定性高 SLA:稳定性是生产系统必备的核心能力,消息来说往往集成在核心交易链路,消息系统应该明确服务的可用性、可靠性指标。使用方应基于明确的 SLA 去设计自己的故障兜底和冗余安全机制。
立足于这个四个关键的演进方向,下面为大家整体介绍一下阿里云 RocketMQ 5.0 在这些方面是如何落地实践的。
大规模弹性:提供匹配业务模型的最佳资源供给能力
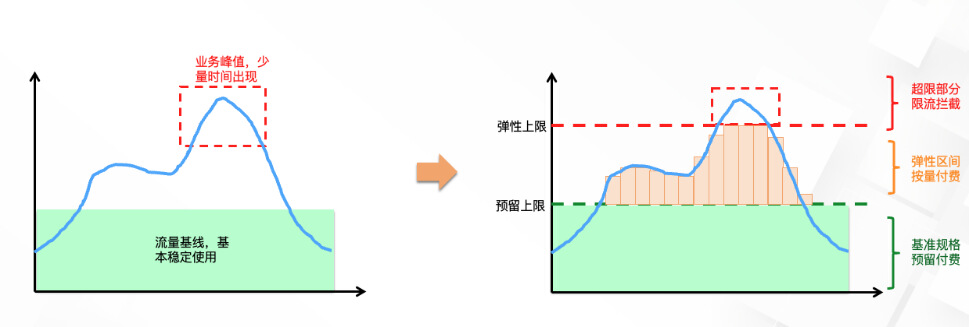
消息服务一般集成在业务的核心链路,比如交易、支付等场景,这一类场景往往存在波动的业务流量,例如大促、秒杀、早高峰等。
面对波动的业务场景,阿里云 RocketMQ 5.0 的消息服务可以伴随业务的诉求进行自适应实现资源扩缩。一方面在比较稳定的业务处理基线范围内,按照最低的成本预留固定的资源;另一方面在偶尔存在的突发流量毛刺时,支持自适应弹性,按量使用,按需付费。两种模式相互结合,可以实现稳定安全的高水位运行,无需一直为不确定的流量峰值预留大量资源。
除了消息处理流量的弹性适应外,消息系统也是有状态的系统,存储了大量高价值的业务数据。当系统调用压力变化时,存储本身也需要具备弹性能力,一方面需要保障数据不丢失,另一方面还需要节省存储的成本,避免浪费。传统的基于本地磁盘的架构天然存在扩缩容问题,其一本地磁盘容量有限,当需要扩大容量时只能加节点,带来计算资源的浪费;其二本地磁盘无法动态缩容,只能基于业务侧流量的隔离下线才能缩减存储成本,操作非常复杂。
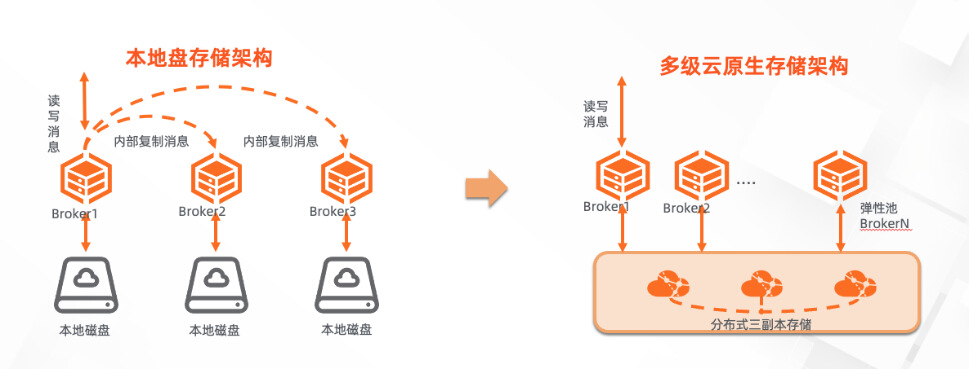
阿里云 RocketMQ 5.0 的消息存储具备天然的 Serverless 能力,存储空间按需使用,按量付费,业务人员只需要按照需求设置合理的 TTL 时间,即可保障长时间存储时的数据完整性。
集成易用性:简化业务开发,降低心智负担和理解成本
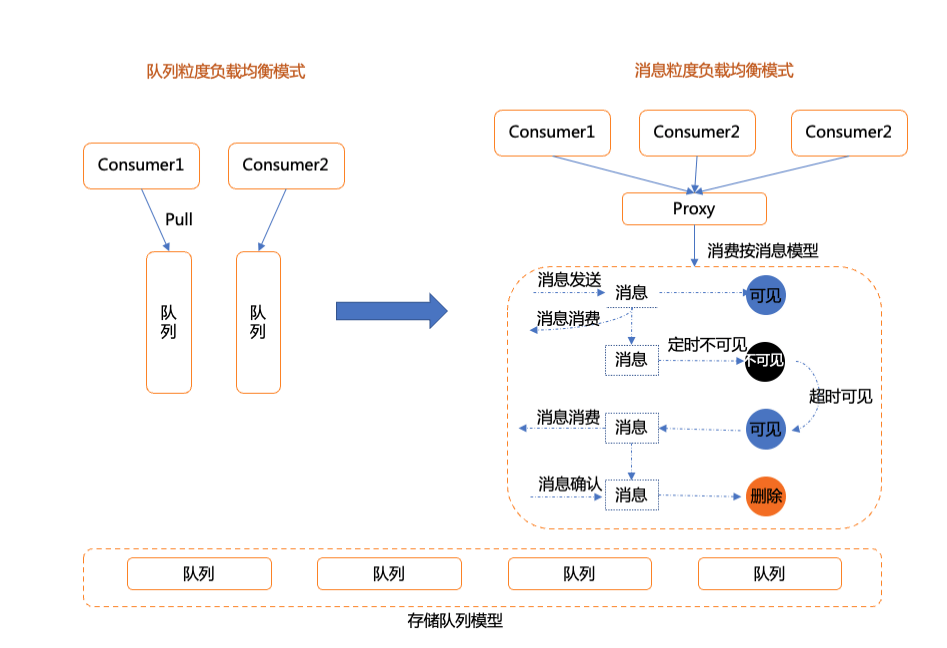
集成易用性是一种系统设计约束,要求消息服务应该从 API 设计到集成开发、再到配置运维,全面地降低用户的负担,避免犯错。举个典型场景,在消息队列例如 RocketMQ 4.x 版本或 Kafka 中,业务消费消息时往往被负载均衡策略所困扰,业务方需要关注当前消息主题的队列数(分区数)以及当前消费者的数量。因为消费者是按照队列粒度做负载均衡和任务分配,只要消费者能力不对等,或者数量不能平均分配,必然造成部分消费者堆积、无法恢复的问题。
在典型的业务集成场景,客户端其实只需要以无状态的消息模型进行消费,业务只需关心消息本身是否处理即可,而不应该关心内部的存储模型和策略。
阿里云 RocketMQ 5.0 正是基于这种思想提供了全新的 SimpleConsumer 模型,支持任意单条消息粒度的消费、重试和提交等原子能力。
可观测性:提供边界清晰、标准开放的自助诊断能力
有运维消息队列经验的同学都会发现,消息系统耦合了业务的上游生产和下游消费处理,往往业务侧出问题时无法清晰地界定是消息服务异常还是业务处理逻辑的异常。
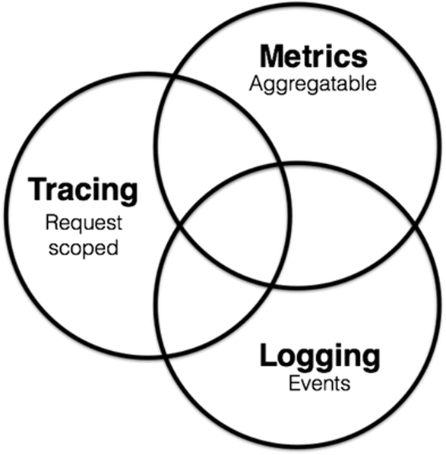
阿里云 RocketMQ 5.0 的可观测性就是为这种模糊不确定的边界提供解法,以事件、轨迹、指标这三个方面为基础,依次从点、线、面的纬度覆盖链路中的所有细节。关于事件、轨迹、指标的定义涵盖如下内容:
- 事件:覆盖服务端的运维事件,例如宕机、重启、变更配置;客户端侧的变更事件,例如触发订阅、取消订阅、上线、下线等;
-
轨迹:覆盖消息或者调用链的生命周期,展示一条消息从生产到存储,最后到消费完成的整个过程,按时间轴抓出整个链路的所有参与方,锁定问题的范围;
-
指标:指标则是更大范围的观测和预警,量化消息系统的各种能力,例如收发 TPS、吞吐、流量、存储空间、失败率和成功率等。
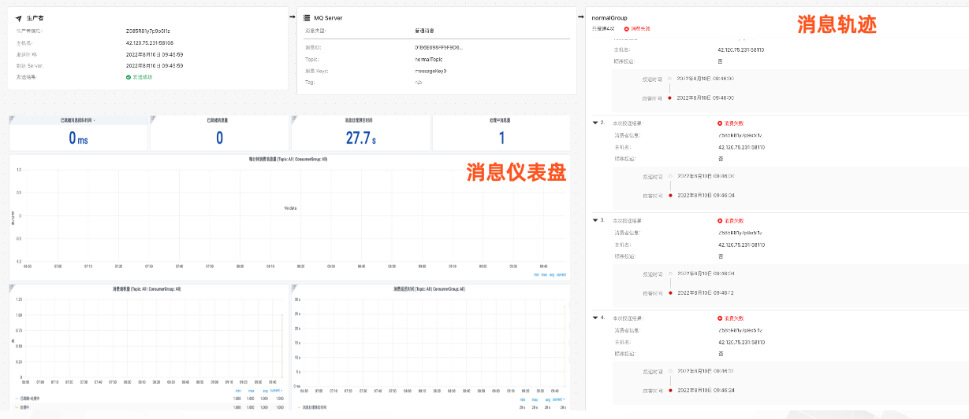
阿里云 RocketMQ 在可观测性方面也是积累良多,不仅率先支持了完善的消息轨迹链路查询,而且在 5.0 新版本中还支持将客户端和服务端的 Trace、Metrics 信息以标准的 OpenTelemetry协议上报到第三方Trace、Metrics中存储,借助开源的 Prometheus 和 Grafana 等产品可以实现标准化的展示和分析。
稳定性 SLA:提供可评估、可量化、边界明确的服务保障能力
稳定性是生产系统必备的核心能力,消息系统往往集成在核心交易链路,消息系统是否稳定直接影响了业务是否完整和可用。但稳定性的保障本身并不只是运维管理,而是要从系统架构的设计阶段开始梳理,量化服务边界和服务指标,只有明确了服务的可用性和可靠性指标,使用方才能设计自己的故障兜底和冗余安全机制。
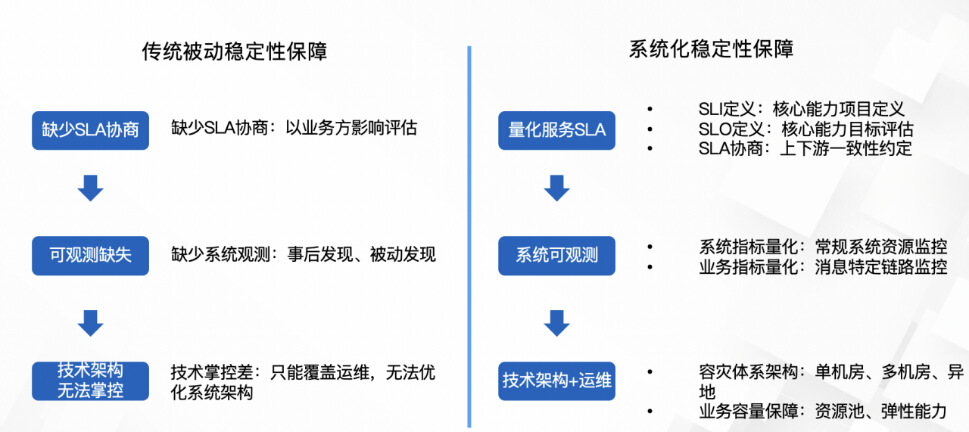
传统的基于运维手段的被动保障方式,只能做基本的扩缩容和系统指标监控,对于消息的各种复杂边界场景,例如消息堆积、冷读、广播等并不能很好的提供量化服务能力。一旦上层业务方触发这些场景,系统则会被打穿,从而丧失服务能力。
阿里云 RocketMQ 5.0 体系化的稳定性建设,是从系统设计阶段就提供对消息堆积、冷读等场景量化服务的能力,确定合理的消息发送 RT、端到端延迟和收发吞吐 TPS 能力等,一旦系统触发这些情况,可在承受范围内做限制和保护。
本篇文章从大规模弹性、集成易用性、可观测性和稳定性 SLA 等方面介绍了 RocketMQ 5.0 的演进和方向,同时针对性介绍了阿里云消息队列 RocketMQ 5.0 在这些方面的实践和落地。
阿里云消息队列 RocketMQ 5.0 目前已正式商业化,在功能、弹性、易用性和运维便捷性等方面进行了全面增强,同时定价相比上一代实例最高降低 50%,助力企业降本增效,以更低的门槛实现业务开发和集成。新一代实例支持 0~100 万 TPS 规模自伸缩、支持突发流量弹性和存储 Serverless;在可观测性方面,支持全链路轨迹集成和自定义 Metrics 集成;在集成易用性方面,支持新一代轻量原生多语言 SDK,更加稳定和易用。
活动推荐
阿里云基于 Apache RocketMQ 构建的企业级产品-消息队列RocketMQ 5.0版现开启活动:
1、新用户首次购买包年包月,即可享受全系列 85折优惠! 了解活动详情:https://www.aliyun.com/product/rocketmq
