
RocketMQ 5.0 API 与 SDK 的演进
RocketMQ 5.0 SDK 采用了全新的 API,使用 gRPC 作为通信层的实现,并在可观测性上做了很大幅度的提升。
全新统一的 API
此处的 API 并不单单只是接口上的定义,同时也规定了各个接口不同的方法和行为,明确了整个消息模型。
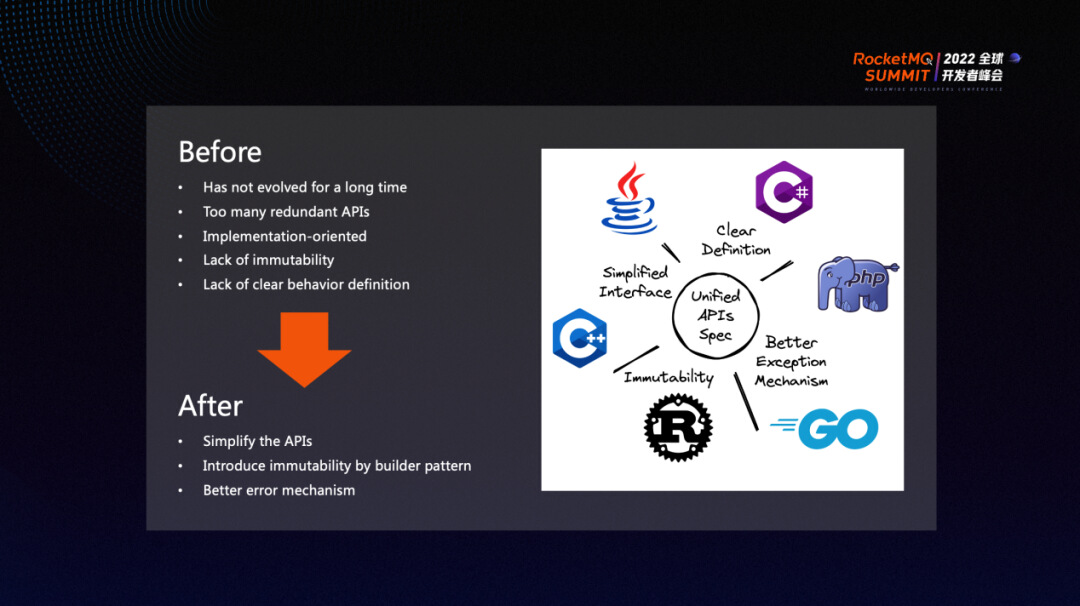
RocketMQ 过去的 API 从第一版开始,至今已经过了很长时间,长期依赖是一个缺乏变革的状态,对于一些中途打算废弃或者变更的 API 也没有进行后续的迭代。此外,接口的定义也不够清晰。因此,RocketMQ 希望在 5.0 中能够建立一个统一的规范,精简整个 API,通过引入 builder 模式来引入更多的不变性,同时做好异常管理,给开发者和用户一个更加清爽的面貌。
目前 C++ 和 Java 已经进行了 5.0 API 的定义与实现,更多语言的支持也陆续在路上了。我们也欢迎更多的开发者可以参与到社区的工作中来。这里给出 5.0 客户端的仓库链接:
除了在上述接口上做的一些修改之外, RocketMQ 5.0 还规定了四种新的不同的客户端类型,即 Producer/Push Consumer/Simple Consumer/Pull Consumer。
其中 Pull Consumer 还在开发中;Producer 主要还是做了接口裁剪,规范了异常管理。在功能上其实并没有做一些颠覆性的改变。Push Consumer 也是比较类似的;Simple consumer 将更多的权利将下发给用户,是一种用户可以主动控制消息接收与处理过程的消费者,特别的,5.0 的 SDK 中,Push Consumer 和 Simple Consumer 都采用 RocketMQ 的 pop 机制进行实现,一些社区的同学可能已经熟悉了。
如果用户并不一定想控制或者关心整个消息的接收过程,只在乎消息的消费过程的话,这个时候 Push Consumer 可能是一个更好的选择。
RocketMQ 5.0 定义了四种不同的消息类型。过去的开源版本中其实我们并没有去突出消息类型这样一个概念,后续出于维护及运维方面的需要以及模型定义的完备,才让今天的 5.0 有了消息类型的这样一个概念。
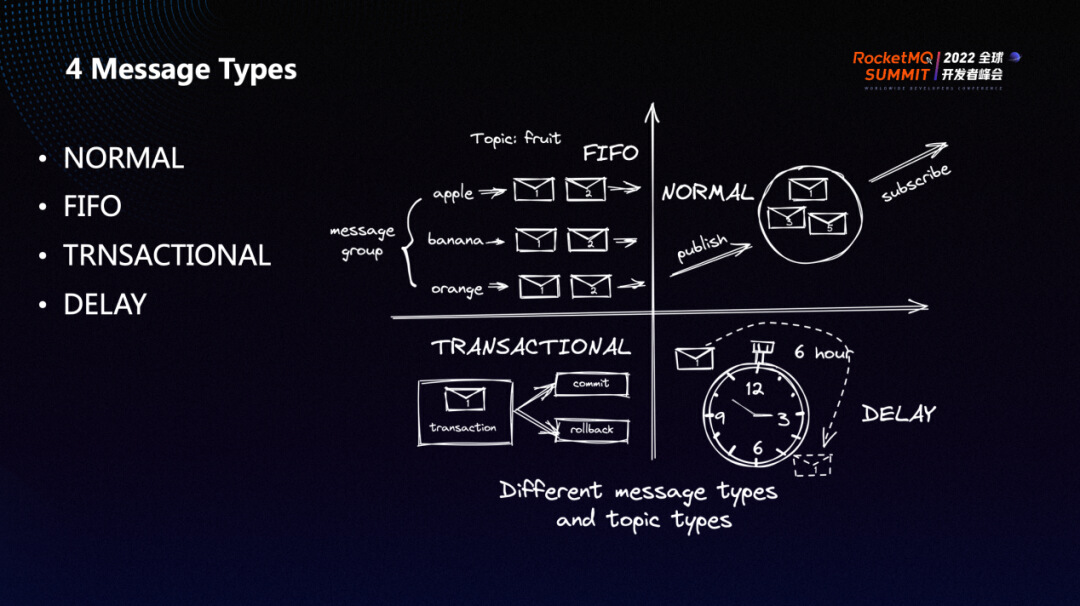
1、NORMAL:普通消息。 2、FIFO:满足先入先出的语义。用户可以通过定义 message group 来控制消息间的消费顺序。例如图中的 fruit 这个 topic 下,可以定义不同的 message group,在 apple 这个 message group 下,会按照发送顺序决定消息被消费的顺序,并且不同的 message group 之间不会互相干扰。 3、TRANSACTIONAL:可以将一条或多条消息包成一个事务,最终用户可以根据自己的业务结果选择提交或者回滚。 4、DELAY:用户可以自主地设置消息的定时时间,相比之前开源版本仅允许用户设置定时/延迟级别,5.0 的实现中还讲允许用户设置更精确的时间戳。
以上四种消息是互斥的,我们会在 topic 的元数据去标识它的类型。实际在消息发送的时候如果如果出现了尝试发送的消息类型与 topic 类型不匹配的情况,也会做一些限制。
实现
RocketMQ 5.0 在客户端的启动过程中提前进行了更多的准备工作。比如用户提前设置要发送消息的 topic 时,Producer 会在启动过程中尝试获取对应 topic 的路由。在过去的客户端实现中,在针对于某个 topic 第一次发送消息时,需要先获取路由,这里就会有一个类似冷启动的过程。
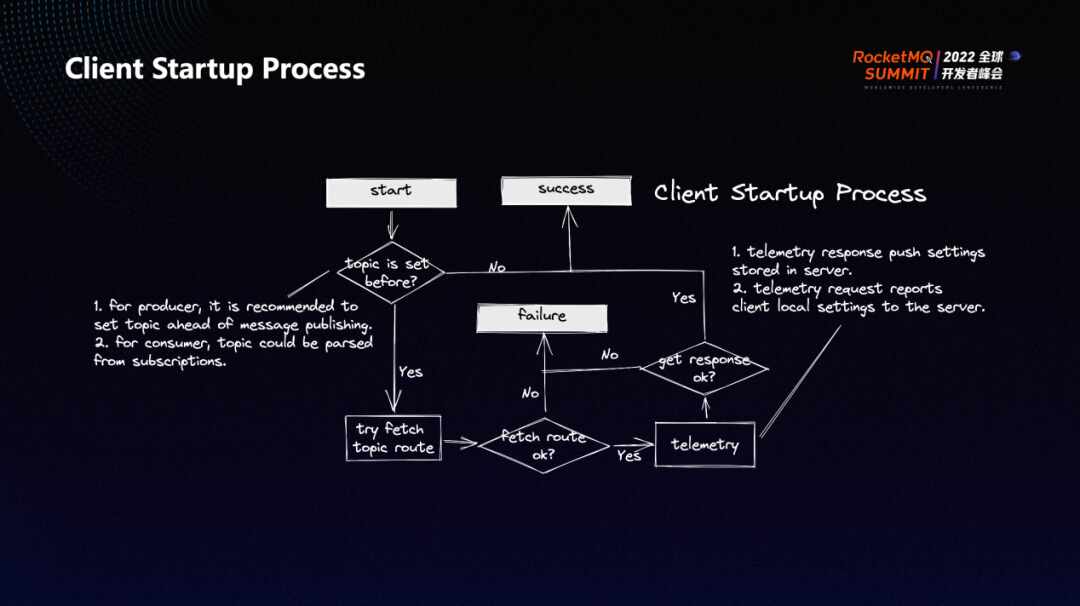
提前获取 Topic 的路由信息有两点好处:
- 不阻塞后面的发送,让消息的发送仅仅触发发送这一个动作。
- 错误前置,比如用户要往一个不存在 Topic 发送消息时,因为路由的获取参与到整个客户端的启动过程,获取路由不成功,那整个客户端启动可能就会失败,用户也是拿不到对应的 Producer 对象的。
类似的,Consumer 的启动也会有这样的一个过程。
除此之外,我们在客户端和服务端之间增加了一个 Telemetry 的部分,它会在客户端和服务端之间建立起了一个进行双向数据通讯的通道,客户端和服务端会在这个过程中沟通配置,比如服务端可以实现对客户端配置的下发,更好地管理客户端。此外,Telemetry 也可以将本地配置主动上报给服务端,让服务端也可以对客户端的设置有更好的了解。Telemetry 通道也会在客户端启动时尝试建立,如果这个通道没有建立成功,也会影响客户端的启动。
总的来说,客户端的启动过程会尽可能将所有准备工作做好。同时在客户端和服务端之间建立 Telemetry 这样一个通讯通道。

客户端内部存在一些周期性的任务,比如路由的定时更新以及客户端往服务端发送心跳等。对于上文中提到的 Telemetry 过程中,客户端的配置上报也是周期性的。
 Producer 在 RocketMQ 5.0 中的具体工作流程
Producer 在 RocketMQ 5.0 中的具体工作流程
消息在发送时,会检查是否已经获取对应 topic 的路由信息。如果已经获取,则尝试在路由中选取队列,随即查看要发送的消息的类型是否与 topic 类型匹配,如果匹配,则进行消息发送。如果发送成功,则返回;否则,判断当前重试次数是否超出用户设置的上限,如果超出,则返回失败;否则轮转到下一个队列,然后对新的队列进行重试直到消费次数超出上线。而如果启动过程中没有提前获取路由,那么消息发送时依然会先尝试获取路由,然后再进行下一步操作。
另外一点相对于老客户端较大的改变在于,客户端从底层 RPC 交互到上层的业务逻辑全部采用异步实现。Producer 依然会提供一个同步发送接口和异步发送接口,但同步的方法也是使用异步来实现,整个逻辑非常统一和清爽。

Push Consumer 分为两部分,消息的接收和消费。
消息接收流程为:客户端需要不断地从服务端拉取消息,并将消息缓存。Push Consumer 会将消息先缓存到客户端的本地,再进行消费,因此它会判断客户端本地的 Cache 是否已满,如果已满,则隔一段时间再判断,直到消息被客户端消费,Cache 尚有余量时再进行消息拉取。为了避免出现一些内存问题,Cache 的大小也是被严格限制的。
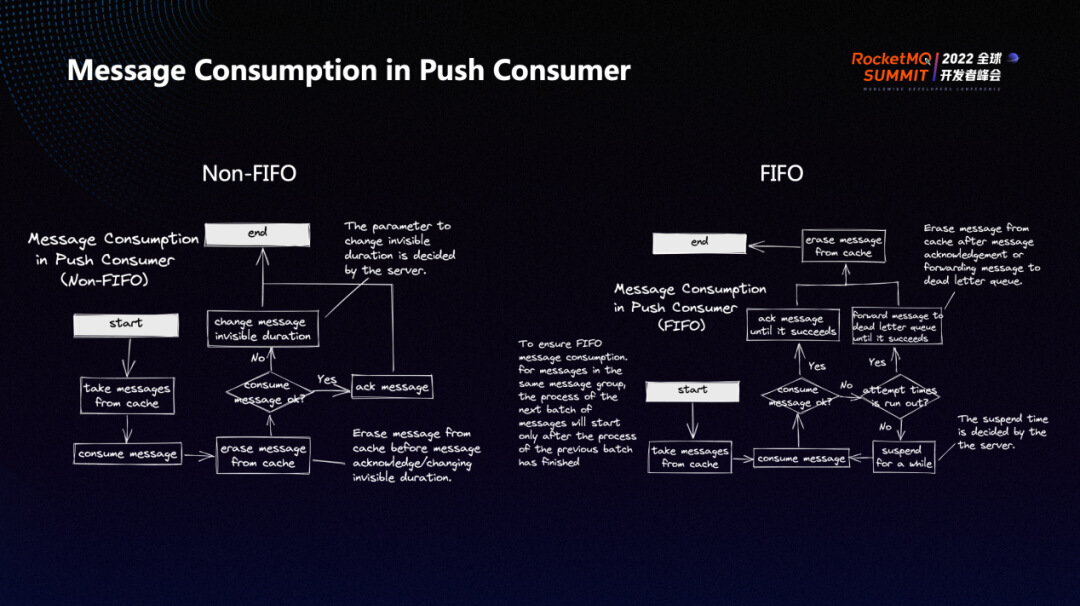
消息消费过程分为两个类型,顺序类型和非顺序类型。
其中非顺序类型即并发消费。消费者会先从 Cache 中获取消息,然后尝试消费消息,消费后再将消息从 Cache 中移除。消息消费成功时,会尝试将消息 ACK ,消费流程结束;如果消费失败,则尝试修改消息的可见时间,即决定下一次什么时候可见。
顺序消费指对于同一个 Group 的消息,最终消费时一定是前一条消息被消费过并且得到确认后,后面的消息才能够继续消费。而消费过程与非顺序消费类似,首先尝试从 Cache 中拉取消息,如果消费成功,则将消息 ACK。ACK 成功后,将其从 Cache 中移除。特别地,如果消费失败,会 suspend 一段时间,然后继续尝试对消息进行消费。此时会判断消费次数是否超限,如果超限,则会尝试将消息放入死信队列中。
相对于非顺序消费,顺序消费更复杂,因为其需要保证前一个消息消费成功后才能对后面的消息进行消费。顺序消费的消费逻辑是基于 message group 隔离的。message group 会在发送时做哈希,从而保证 message group 的消息最终会落在一个队列上,顺序消费模式本质上保证队列内部消费的顺序。
此外,因为不同 message group 的顺序消息最终可能会映射到同一个队列上,这可能会导致不同的 message group 之间的消费形成阻塞,因此服务端未来会实现一个虚拟队列,让不同的 message group 映射到客户端的虚拟队列,保证他们之间没有任何阻塞,从而加速数据消息的消费过程。

对于 Simple Consumer,用户可以主动控制消息接收和确认的流程。比如用户收到消息后,可以根据业务决定是否过一段时间再消费该消息,或者不需要再收到该消息。消费成功后将消息 ACK 掉,如果失败则主动修改可见时间,选择该消息下一次什么时候可见,即由用户自发地控制整个过程。
可观测性
Shaded Logback
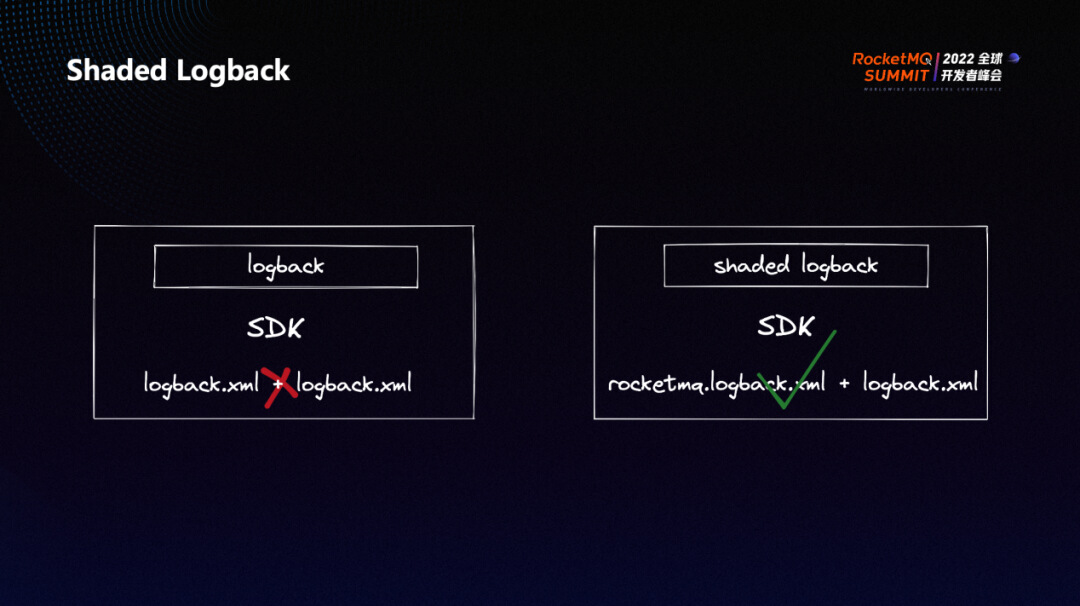
因为历史原因,RocketMQ 的老客户端并不是面向 SLF4J 进行编程的,而是面向 logback 的。这么做的目的其实是为了方便快捷地获取日志,不需要让用户自己去手动配置。
RocketMQ 中专门有一个 logging 模块是负责日志部分的,像用户自己使用了 logback ,RocketMQ SDK 如果也直接去使用 logback,两者就会产生各种各样的冲突,这个 logging 模块就是用来保证这一层隔离性的。
但是 logging 模块本身的实现并不是很优雅,也带来了一定的维护成本。因此我们采用了 shade logback 的方式来达到上文提到的隔离性。shaded logback 不仅能够避免用户的 logback 与 RocketMQ 自己的 logback 冲突,还能保持较好的可维护性,将来要想在日志上去做一些修改,也来得容易的多。
具体来说,用户的 logback 会采用 logback.xml 的配置文件,通过 shade logback, RocketMQ 5.0 的客户端会使用 rocketmq.logback.xml 的配置文件,因此在配置部分就已经完全隔离了,同时在 shade 的过程中,还对原生 logback 中使用到的一些环境变量和系统变量也进行了修改,这样就保证了两者的彻底隔离。
另外,使用 shadeed logback 之后,RocketMQ 5.0 客户端中的日志部分就全都是面向 SLF4J 来进行编程的了,这样一来,如果我们未来想让用户自己去完全控制日志的话,提供一个去除 logback 的 SDK 就可以了,非常方便。
Trace
5.0 的消息轨迹基于 OpenTelemetry 模型进行定义与实现,消息发送或接收消息的流程被定义为一个个独立的 span ,这一套 span 规范参照了 OpenTelemetry 关于 Messaging 的定义。图中这里 Process P 表示 Producer ,Process C 表示 Consumer。消息的全生命周期,从发送到接收到消费,就可以具象化为这样一个个的 span。
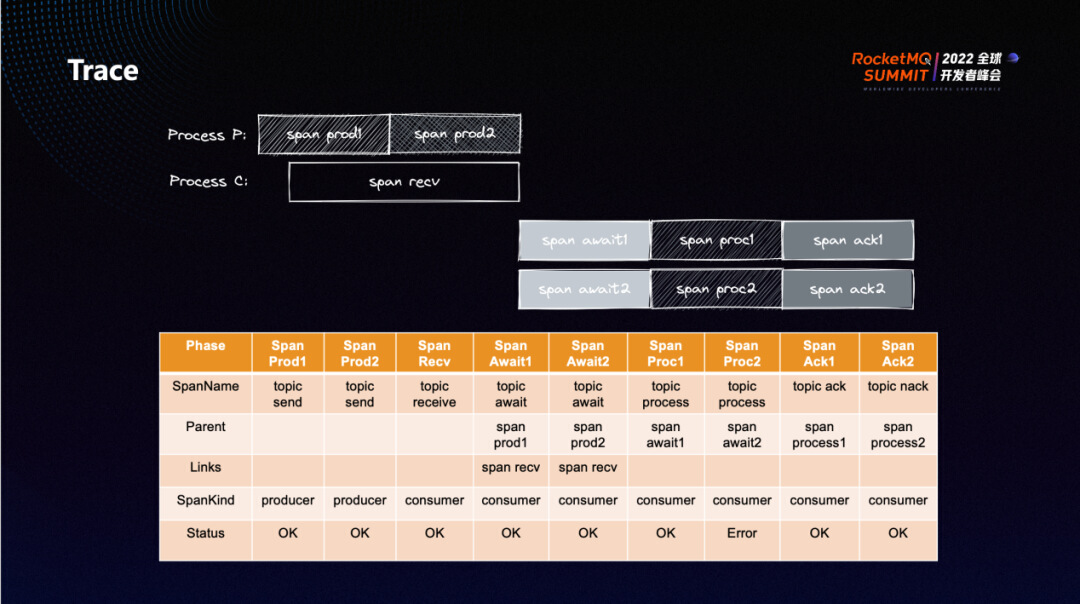
比如,针对 Push Consumer 而言,先会有一个 receive 的 span 来表示从服务端获取消息的过程,收到消息后到会先等待消息被处理,这个也就是 await span 表示的过程,消息被处理则对应图中的 process span,消息消费结束之后,向服务端反馈消息处理结果也会有专门的 span 进行描述。
我们通过 parent 和 link 来讲所有的这些 span 关联起来,这样通过一条消息的任意一个 span,就可以获得这条消息全生命周期的所有 span。
不仅如此,用户还将允许可以设置一个 span context 与自己的业务链路进行关联,将 RocketMQ 5.0 的消息轨迹本身嵌入进自己的全链路可观测系统中去。
Metrics
Tracing 相对来说成本是比较高的,因为一条消息从发送到接收,可能会有很多流程,这就伴随着很多的 span,这就导致相对来说,tracing 数据的存储查询成本相对来说比较高。我们希望诊断整个 SDK 的健康状况,同时又不希望收集太多的 tracing 信息提高成本,此时提供一份 metrics 数据就能比较好地满足我们的需求。

在 SDK 的 metrics 中我们新增了诸多指标,包括不限于 Producer 中消息发送延时,Push Consumer 中消息的消费耗时和消息缓存量,可以帮助用户和运维者更快更好地发现异常。
5.0 中 SDK 的 metrics 也是基于 OpenTelemetry 进行实现的。以 Java程序为例,OpenTelemetry 对于 Java 的实现本身提供了一个 agent,agent 在运行时会打点采集 SDK 的一些 tracing/metrics 信息,并将它上报到对应的 metric collector 中,这种通过 agent 来降低无侵入式数据采集的方式被称之为 automatic instrumentation,而手动在代码中实现打点采集的方式则被称之 manual instrumentation。对于 metrics 我们目前还是采用 manual instrumentation 的方式来进行数据的采集和上报的。服务端会告知客户端对应的 collector 的地址,然后客户端将 Metrics 数据上传到对应的 collector 当中去。
作者介绍: 艾阳坤,Apache RocketMQ 5.0 Java SDK 作者,CNCF Envoy Contributor,CNCF OpenTelemetry Contributor,阿里云智能高级开发工程师。
活动推荐
阿里云基于 Apache RocketMQ 构建的企业级产品-消息队列RocketMQ 5.0版现开启活动:
1、新用户首次购买包年包月,即可享受全系列 85折优惠! 了解活动详情:https://www.aliyun.com/product/rocketmq
