深度剖析 RocketMQ 5.0 之 IoT 消息:物联网需要什么样的消息技术?
简介: 本文来学习一个典型的物联网技术架构,以及在这个技术架构里面,消息队列所发挥的作用。在物联网的场景里面,对消息技术的要求和面向服务端应用的消息技术有什么区别?学习 RocketMQ 5.0 的子产品 MQTT,是如何解决这些物联网技术难题的。
1.前言
从初代开源消息队列崛起,到 PC 互联网、移动互联网爆发式发展,再到如今 IoT、云计算、云原生引领了新的技术趋势,消息中间件的发展已经走过了 30 多个年头。
目前,消息中间件在国内许多行业的关键应用中扮演着至关重要的角色。随着数字化转型的深入,客户在使用消息技术的过程中往往同时涉及交叉场景,比如同时进行物联网消息、微服务消息的处理,同时进行应用集成、数据集成、实时分析等,企业需要为此维护多套消息系统,付出更多的资源成本和学习成本。
在这样的背景下,2022 年,RocketMQ 5.0 正式发布,相对于 RocketMQ 4.0,架构走向云原生化,并且覆盖了更多的业务场景。想要掌握最新版本 RocketMQ 的应用,就需要进行更加体系化的深入了解。
2.背景
本节课分为三个部分,第一部分,我们来学习一个典型的物联网技术架构,以及在这个技术架构里面,消息队列所发挥的作用。第二部分我们会讲在物联网的场景里面,对消息技术的要求和面向服务端应用的消息技术有什么区别?第三部分,我们会学习 RocketMQ 5.0 的子产品 MQTT,是如何解决这些物联网技术难题的。
3. 物联网消息场景
我们先来了解一下物联网的场景是什么,以及消息在物联网里面有什么作用。
物联网肯定是最近几年最火的技术趋势之一,有大量的研究机构、行业报告都提出了物联网快速发展的态势。首先是物联网设备规模爆发式增长,预测会在 2025 年达到 200 多亿台。
其次是物联网的数据规模,来自物联网的数据增速接近 28%,并且未来有 90% 以上的实时数据来自物联网场景。这也就意味着未来的实时流数据处理数据类型会有大量物联网数据。
最后一个重要的趋势是边缘计算,未来会有 75% 的数据在传统数据中心或者云环境之外来处理,这里的边缘指的是商店、工厂、火车等等这些离数据源更近的地方。由于物联网产生的数据规模很大,如果全部数据传输到云端处理,会面临难以承受的成本,应该充分利用边缘的资源直接计算,再把高价值的计算结果传输云端;另一方面,在离用户近的地方计算直接响应,可以降低延迟,提升用户体验。
物联网的发展速度这么快,数据规模那么大,跟消息有什么关系呢?我们通过这个图来看一下消息在物联网场景发挥的作用:
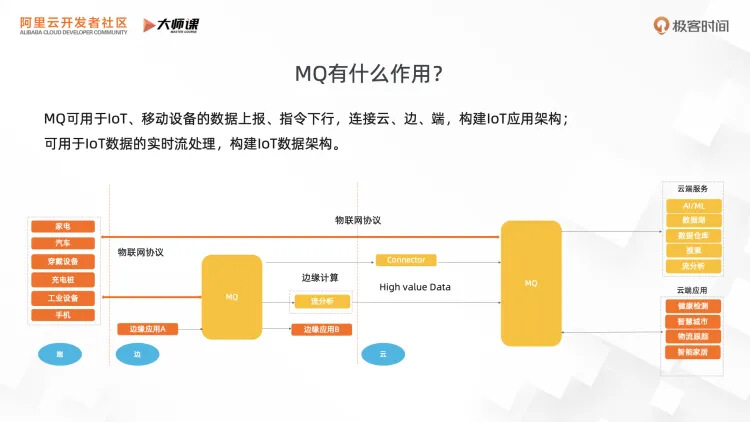
第一个作用是连接,承担通信的职责,支持设备和设备的通信,设备和云端应用的通信,比如传感器数据上报、云端指令下发等等这些功能,支撑 IoT 的应用架构,连接云边端。
第二个作用是数据处理,物联网设备源源不断的产生数据流,有大量需要实时流处理的场景,比如设备维护,高温预警等等。基于 MQ 的事件流存储和流计算能力,可以构建物联网场景的数据架构。
4. 物联网消息技术
下面我们来看看在物联网场景里,对消息技术有什么诉求?我们先从这个表格来分析物联网消息技术跟之前我们讲的经典消息技术有什么区别?
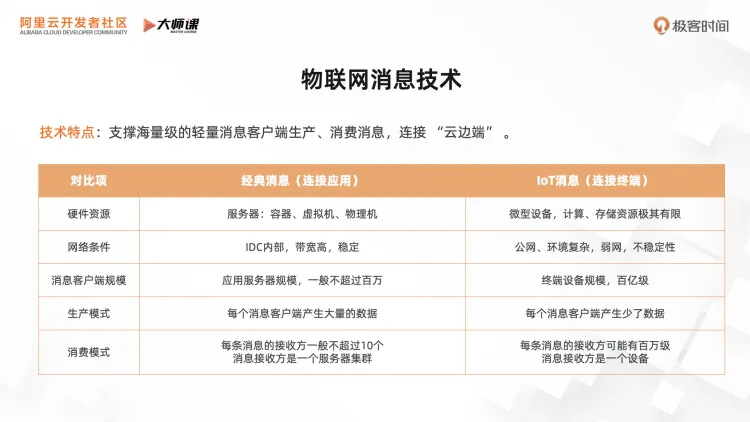
经典的消息主要是为服务端系统提供发布订阅的能力,而物联网的消息技术是为物联网设备之间、设备和服务端之间提供发布订阅的能力。我们来分别看一下各自场景的特点。
在经典消息场景里,消息 broker、消息客户端都是服务端系统,这些系统都是部署在 IDC 或者公共云环境。无论是消息客户端、消息服务端,都会部署在配置比较不错的服务器机型,有容器、虚拟机、物理机等等这些形式。同时,客户端和消息服务端一般都是部署在同一个机房,属于内网环境,网络带宽特别高,而且网络质量稳定。客户端的数量一般对应到应用服务器的数量,规模较小,一般都是数百、数千台服务器,只有超大规模的互联网公司才能达到百万级。从生产消费的角度来看,每个客户端的消息生产发送量一般对应到其业务的 TPS,能达数百数千的 TPS。在消息消费方面,一般是采用集群消费,一个应用集群共享一个消费者 ID,共同分担该消费组的消息。每条消息的订阅比一般也不高,正常情况下不会超过 10 个。
而在 IoT 消息场景,很多条件都不一样,甚至是相反的。IoT的消息客户端是微型设备,计算存储资源都很有限,消息服务端可能要部署在边缘环境,使用的服务器配置也会比较差。另一方面物联网设备,一般是通过公网的环境来连接的,它的环境特别复杂,而且经常会不断移动,有些时候会断网或处于弱网环境,网络质量差。物联网场景中,消息的客户端实例数对应到物联网设备数,可以到亿级别,比大型互联网公司的服务器数量要大很多。每个设备的消息 tps 不高,但是一条消息有可能同时被百万级的设备接受,订阅比特别高。
5. RocketMQ - MQTT
从这里可以看出,物联网需要的消息技术和经典的消息设计很不一样。接下来我们再来看,为了应对物联网的消息场景,RocketMQ 5.0 做了哪些事情?RocketMQ 5.0 里面,我们发布了一个子产品,叫做 RocketMQ - MQTT。它有三个技术特点:
首先,它采用的标准的物联网协议 MQTT,该协议面向物联网弱网环境、低算力的特点设计,协议十分精简。同时有很丰富的特性,支持多种订阅模式,多种消息的 QoS,比如有最多一次,最少一次,当且仅当一次。它的领域模型设计也是 消息、 主题、发布订阅等等这些概念,和 RocketMQ 特别匹配,这为打造一个云端一体的 RocketMQ 产品形态奠定了基础。
第二,它采用的是纯算分离的架构。RocketMQ Broker 作为存储层,MQTT 相关的领域逻辑都在 MQTT Proxy 层实现,并面向海量的连接、订阅关系、实时推送深度优化,Proxy 层可以根据物联网业务的负载独立弹性,如连接数增加,只需要新增 proxy 节点。
第三,它采用的是端云一体化的架构,因为领域模型接近、并且以 RocketMQ 作为存储层,每条消息只存一份,这份消息既能被物联网设备消费,也能被云端应用消费。另外 RocketMQ 本身是天然的流存储,流计算引擎可以无缝对 IoT 数据进行实时分析。

5.1. IoT 消息存储模型
接下来我们再从几个关键的技术点,来深入了解 RocketMQ 的物联网技术实现。
5.1.1. 读放大为主,写放大为辅
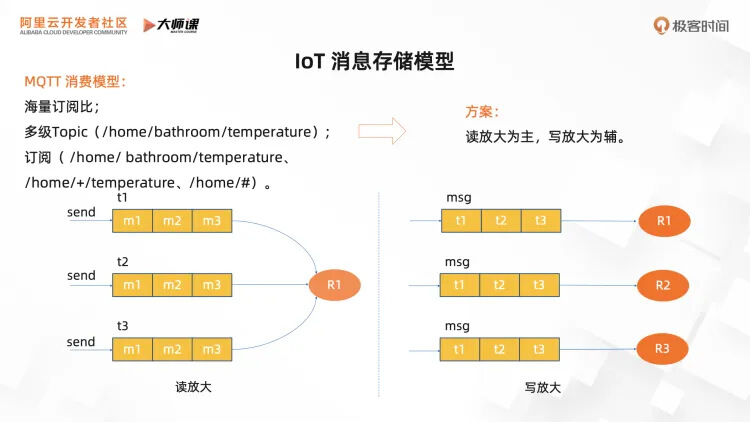
首先要解决的问题是物联网消息的存储模型,在发布订阅的业务模型里,一般会采用两种存储模型,一种是读放大,每条消息只写到一个公共队列,所有的消费者读取这个共享队列,维护自己的消费位点。另外一种模型是写放大模型,每个消费者有自己的队列,每条消息都要分发到目标消费者的队列中,消费者只读自己的队列。
因为在物联网场景里,一条消息可能会有百万级的设备消费,所以,很显然,选择读放大的模型能显著降低存储成本、提高性能。
但是,只选择读放大的模式没法完全满足要求,MQTT 协议有其特殊性,它的 Topic 是多级 Topic,而且订阅方式既有精准订阅,也有通配符匹配订阅。比如在家居场景,我们定义一个多级主题,比如家/浴室/温度,有直接订阅完整多级主题的 家/浴室/温度,也有采用通配符订阅只关注温度的,还有只关注一级主题为 家的所有消息。
对于直接订阅完整的多级主题消费者可以采用读放大的方式直接读取对应多级主题的公共队列;而采用通配符订阅的消费者无法反推消息的 Topic,所以需要在消息存储时根据通配符的订阅关系多写一个通配符队列,这样消费者就可以根据其订阅的通配符队列读取消息。
这就是 RocketMQ 采用的读放大为主,写放大为辅的存储模型。
5.1.2. 端云一体化存储
基于上节课的分析,我们设计了 RocketMQ 端云一体化的存储模型,看下这张图。
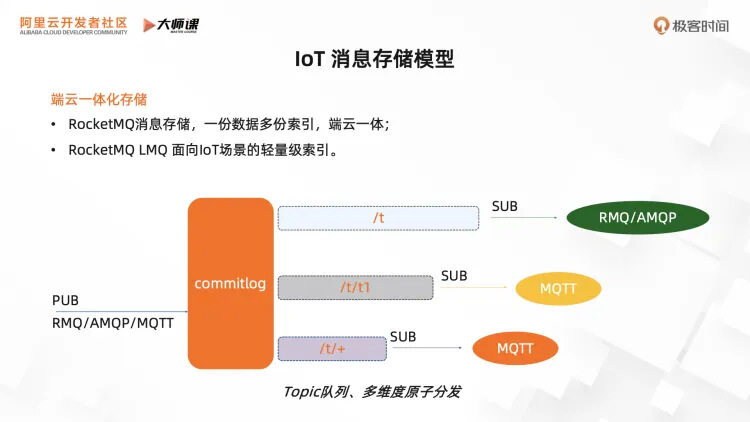
消息可以来自各个接入场景(如服务端的 RMQ/AMQP,设备端的 MQTT),但只会写一份存到 commitlog 里面,然后分发出多个需求场景的队列索引,比如服务端场景(MQ/AMQP)可以按照一级 Topic 队列进行传统的服务端消费,设备端场景可以按照 MQTT 多级 Topic 以及通配符订阅进行消费消息。
这样我们就可以基于同一套存储引擎,同时支持服务端应用集成和 IoT 场景的消息收发,达到端云一体化。
5.2. 队列规模问题
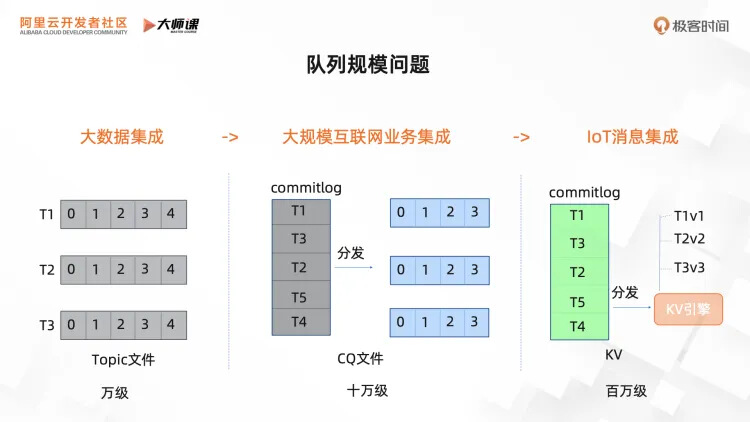
我们都知道像 Kafka 这样的消息队列每个 Topic 是独立文件,但是随着 Topic 增多消息文件数量也增多,顺序写就退化成了随机写,性能明显下降。RocketMQ 在 Kafka 的基础上进行了改进,使用了一个 Commitlog 文件来保存所有的消息内容,再使用 CQ 索引文件来表示每个 Topic 里面的消息队列,因为 CQ 索引数据比较小,文件增多对 IO 影响要小很多,所以在队列数量上可以达到十万级。但是这个终端设备队列的场景下,十万级的队列数量还是太小了,我们希望进一步提升一个数量级,达到百万级队列数量,所以,我们引入了 Rocksdb 引擎来进行 CQ 索引分发。
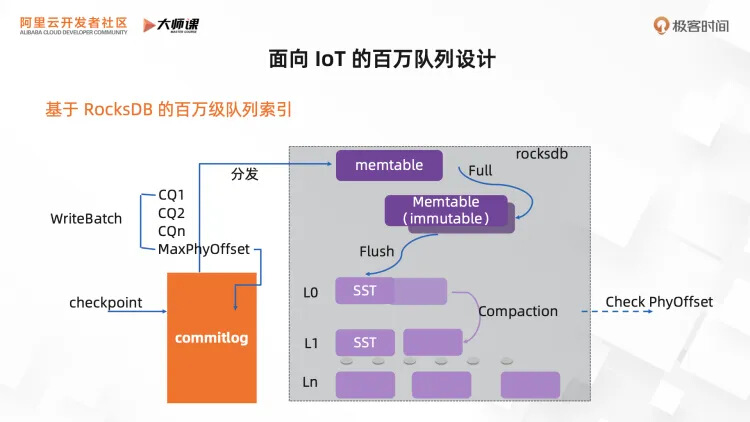
面向 IoT 的百万级队列设计
Rocksdb 是一个广泛使用的单机 KV 存储引擎,有高性能的顺序写能力。因为我们有了 commitlog 已具备了消息顺序流存储,所以可以去掉 Rocksdb 引擎里面的 WAL,基于 Rocksdb 来保存 CQ 索引。在分发的时候我们使用了 Rocksdb 的 WriteBatch 原子特性,分发的时候把当前的 MaxPhyOffset 注入进去,因为 Rocksdb 能够保证原子存储,后续可以根据这个 MaxPhyOffset 来做 Recover 的 checkpoint。最后,我们也提供了一个 Compaction 的自定义实现,来进行 PhyOffset 的确认,以清理已删除的脏数据。
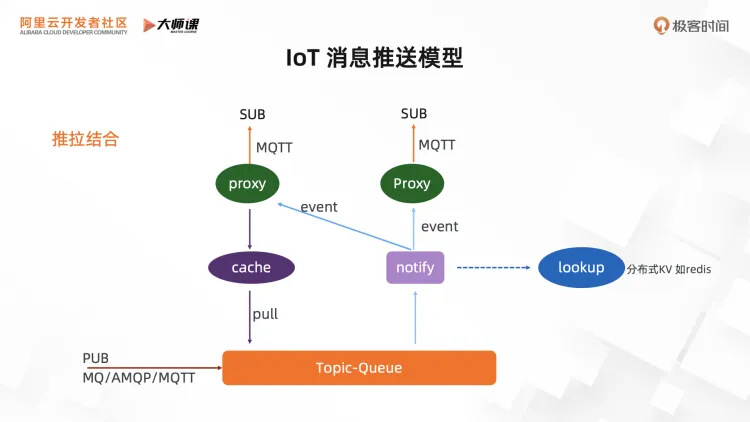
5.3. IoT 消息推送模型
介绍了底层的队列存储模型后,我们再详细描述一下匹配查找和可靠触达是怎么做的。在 RocketMQ 的经典消费模式里,消费者是直接采用长轮询的方式,从客户端直接发起请求,精确读取对应的 topic 队列。而在 MQTT 场景里,因为客户端数量、订阅关系数量规模巨大,无法采用原来的长轮询模式,消费链路的实现更加复杂。这里使用的是推拉结合的模型。
这里展示的是一个推拉模型,终端设备通过 MQTT 协议连到 Proxy 节点。消息可以来自多种场景(MQ/AMQP/MQTT)发送过来,存到 Topic 队列后会有一个 notify 逻辑模块来实时感知这个新消息到达,然后会生成消息事件(就是消息的 Topic 名称),把这个事件推送至网关节点,网关节点根据它连上的终端设备订阅情况进行内部匹配,找到哪些终端设备能匹配上,然后会触发 pull 请求去存储层读取消息,再推送终端设备。
一个重要问题,就是 notify 模块怎么知道一条消息在哪些网关节点上面的终端设备感兴趣,这个其实就是关键的匹配查找问题。一般有两种方式:第一种,简单的广播事件;第二种,集中存储在线订阅关系(比如图里的 lookup 模块),然后进行匹配查找,再精准推送。事件广播机制看起来有扩展性问题,但是其实性能并不差,因为我们推送的数据很小,就是 Topic 名称,而且相同 Topic 的消息事件可以合并成一个事件,我们线上就是默认采用的这个方式。集中存储在线订阅关系,这个也是常见的一种做法,如保存到 RDS、Redis 等等,但要保证数据的实时一致性也是有难度的,而且要进行匹配查找对整个消息的实时链路RT开销也会有一定的影响。
这幅图里还有一个 Cache 模块,用来做消息队列 cache,避免在大广播比场景下每个终端设备都向存储层发起读数据情况。